cadence, temporal,principles,desigon, workflow,activity
** Designing A Workflow Engine from First Principles(.part1)**
이글은 Temporal의 Designing A Workflow Engine from First Principles을 번역한 글입니다.
이렇게 표시된 항목에는 필자의 해석이 달려있습니다.
Four Properties of a Workflow
-
workflow의 정의는 아래와 같습니다.
- 탄력적인 프로그램
- 테스크를 실행
- 외부이벤트에 반응(timer 와 timeout 등)
-
탄력적이라는 얘기는 장애(infra중단 및 availabitiy zones 다운등)에 프로그램이 게속 실행되는것을 말합니다.
-
대게 프로그램은 tasks의 sequensce로 조직되고, 외부 이벤트와 반응하고 시간에 잘 처리되야됩니다. time,과 timeout은 비즈니스 레벨의 프로스세중 중요한 요소입니다.
즉 이전 cadence가 말했던 fault oblivious 하다는게 특징.
Workflow as State machine
- 고 레벨에서 어떤 workflow engine은 상태 머신입니다. 당신은 task를 실행하고 외부 이벤트에 반응하는 순서를 정의해야합니다.
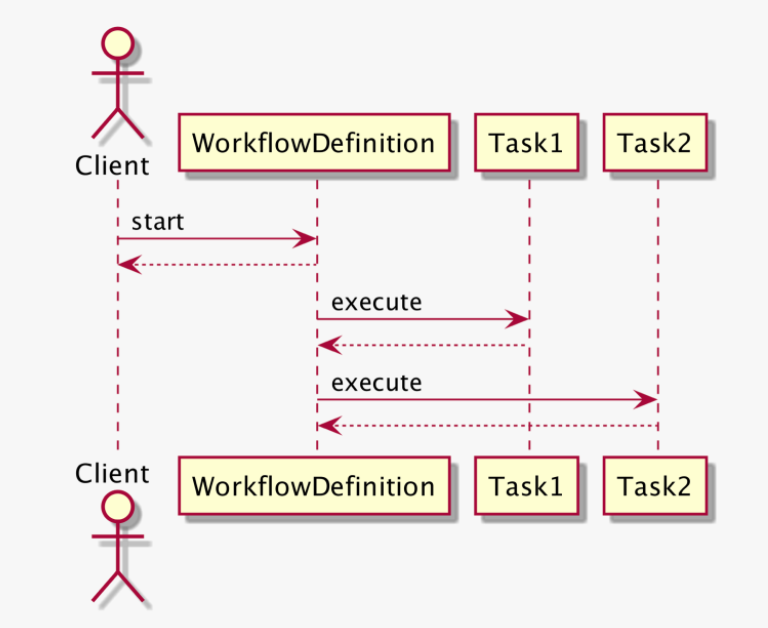
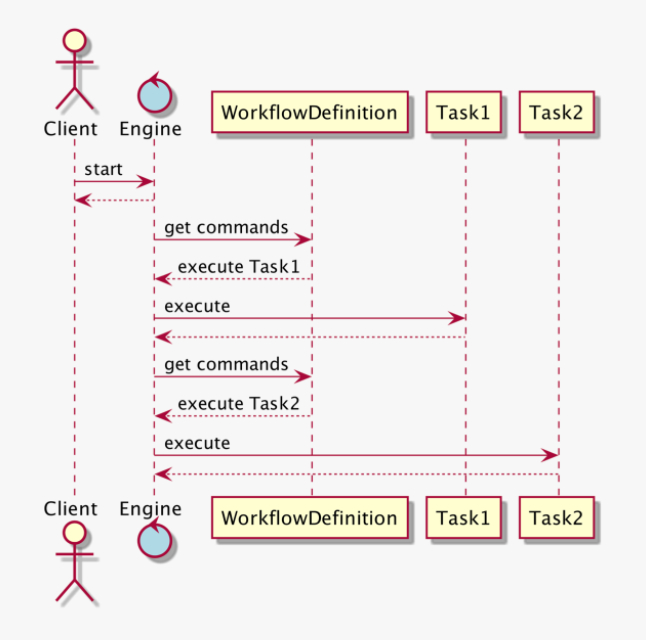
위 다이어그램을 보면:
-
엔진은 상태머신에 현재 상태를 workflowDefinition 정의합니다
-
worklfowDefitino은 런하기위해 다음 커맨드를 리턴합니다
-
첫번째 커맨드는 run Task1
-
그리고, 엔진은 task1이 complete되었다고 workflowDefitiniton에 알립니다.
-
다시 상태 머신은 정의하고 다음 command를 찾습니다.
-
다음 command는 run Task2
상태 머신이 cadence cluster의 어느 부분을 이야기하고, 결국
workflwo Definition이라는 녀석이 enging으로 부터 task실행 command을 얻어오고 실행하며 실제 일하는 녀석이 될것입니다.
Using Task Queues
- 실제 시스템에서 task를 바로 콜하기 원하지 않을것이다, 왜냐면 flow control, 가용성, 속도저하등의 문제가 있음으로, 그래서 queue에 dispatch task 를 dispatch하는방식이 매우 일방적인 기술이다.
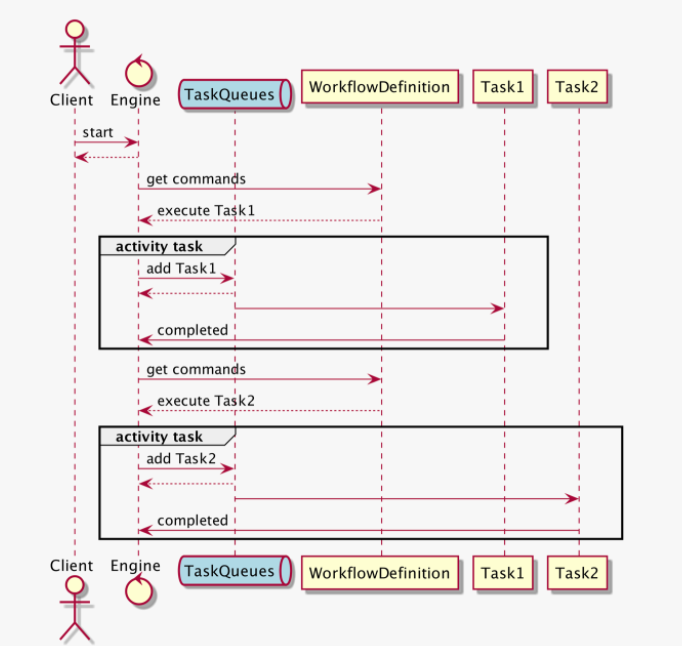
-
모든 부분 workflow enging은 queue를 사용하여 task를 worker에게 전달한다
최초 그림처럼 엔진이 바로 실행하는게 아니라 queue로 관리한다. 이야기한 것처럼, queue를 사용하면 많은 taks들을 분리하기 쉽고, 확장하기가 쉬워지니까
Timer Queue
- 시간은 중요하다
- 매 task 호출에는 timeout이 있어야한다
- workflow 자체도 timeout 이 있다
- 30days sleeping과 같은 실행도 가능해야한다.
- 그래서 위같은 타이머를 지속적으로 저장하고 전달하는 외부 timer 서비스 혹은 timer queue가 필요하다
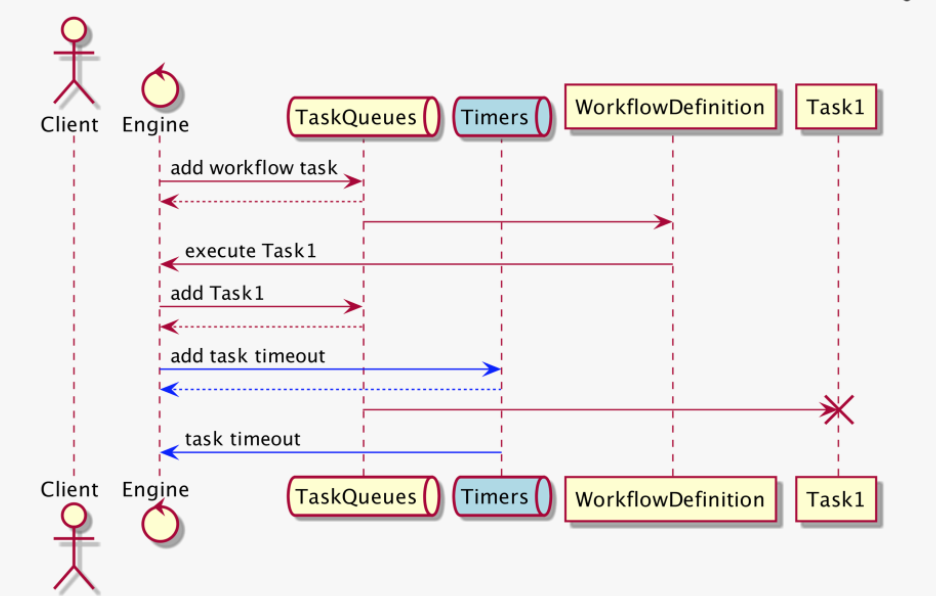
만약 workflowSleep등이 있다면 여기서 언급된 timerQueue를 이용해 별도로 처리하게 된다. workflow나 activity등의 timeout역시 저녀석으로 관리될것이다.
Consistency and importnace of Transactions
-
workflow가 시작할때마다 아래정보를 수행할수있도록 상태를 저장해야합니다.
- database에 create state
- create timer
- workflowDefinition 선택할수있도록 taskqueue에서 task를 pull합니다.
- 작업을 업데이트, 생성하고 상태를 업데이트하는데 필요하하는 명령어를 제공할때
-
이런 업데이트는 여러 데이터소스로부터 꼭 transactional하게 동작해야합니다.
workflow가 실행되는데 상태와, timer등의 생성 사용, 업데이트(즉 동작의 대부분)이 transactional 해야한다
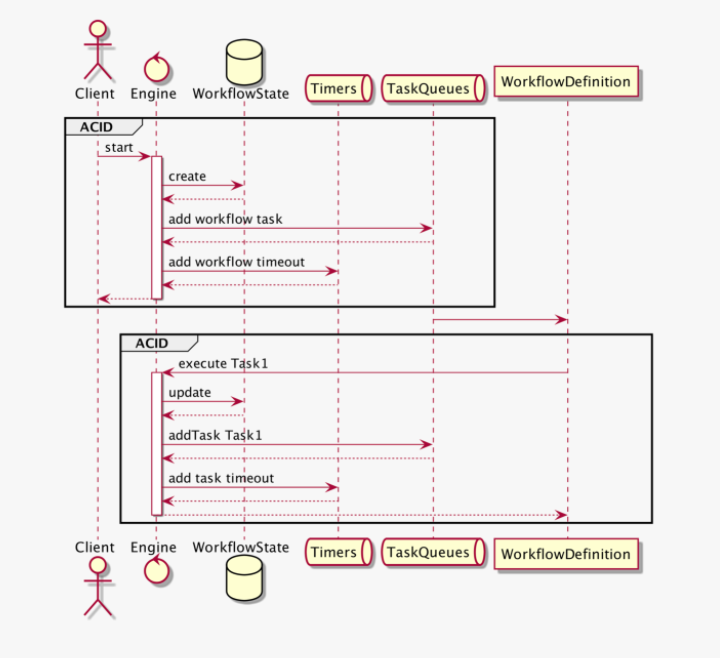
-
위에 그림은 꼭 저장해라!
-
이런 모든 구성요소에 대해 transaction이 없는 워크플로우엔진에서 실행하면, 모든 종류의 race condition이 발생합니다.
-
상태를 업데이트하고, task를 taks queue에 넣고 상태업데이트를 진행하지만, task queue가 실패하면 시스템은 미해결 작업이 있다고 생각하지만 작업은 없는 상태로 끝납니다
-
state update⇒ queue에 넣는 과정이 transaction 해야한다고 말하는것. status는 업데이트 되었기에 queue에 삽이된걸로 인지할것이나 실제 queue에는 들어가지않아 실행이 안되는 상태.
-
만약 task를 task queue에 먼저넣고 상태 업데이트를 하면 업데이트가 느린경우 task전달되고 처리되는 시간까지 처리될수있음으로 inconsistent하고 엣지 케이스처리가 필요할 수 있다
task queue에 먼저넣으면 state update가 느려지면 실제 상태가 업데이트실패할경우 다시 incsonsitent하다 결국엔 consistent 하게 만들어줄 무언가가 필요하단 이야기
-
-
이런 업데이트가 transactional하다면 모든 race condition은 사라질것입니다. 시스템은 단순해지고 어플레키이션 레벨의 코드는 더이상 엣지케이스를 볼필요없고 프로그래밍 모델을 단순화합니다.
-
이는 워크플로 엔진 구현에만 적용되는 것은 아닙니다. 대부분의 엔지니어는 서비스를 작성하기 위해 워크플로와 같은 오케스트레이터나 워크플로 엔진을 사용하지 않습니다. 대기열, 데이터베이스 및 기타 데이터 소스를 사용하여 트랜잭션이 없는 hodgepodge 아키텍처를 생성합니다.
-
이것은 이해하는 것이 매우 중요합니다. 이러한 구성 요소로 시스템을 구축하는 경우 racecondition에서의 극단적인 경우가 발생하게 됩니다 . 따라서 Temporal의 기본 아키텍처와 같은 강력한 엔진을 사용하면 삶이 엄청나게 간소화됩니다.
Scalabiltiy Needs
workflow 엔진은 task queus나 timer 그리고 상태 와 transaction update를 전부 처리해야되기때문에 어렵습니다. 당신이 이런 요구사항을 가지고 엔진을 찾는다면, 많은 구현들이 하나의 데이터베이스거나 하나의 프로세스로 사용됩니다. 만약 그것이 당신이 필요로하는 전부라면 트랜적션 요구사항은 쉽게 해결됩니다. 그러나 스케일러블하지 않습니다.
- 분산환경이 아닌 단일 디비 형태는 위같은 고민이 필요 없지만, scailability를 보장하면서 consenseous를 만족시키는 작업은 그 복잡도가 크게 증가한다.
scalability의 관점에서 무엇이 우리에게 중요한가? 어떻게 수백만의 작업들을 처리할 수 있을까요?
우리는 naive하게 다수의 머신을 생성하는 거대한 single workflow를 만들 수 있습니다. 예를들어, MapReduce를 사용하면 수천대의 머신에서 실행되는 single pipeline을 작성할 수 있습니다. 그러나 temporal은 다른 방법을 선택했습니다.
- Workflow as unit of scalability: temporal의 usecase의 경우, single workflow로 인스턴스를 확장하지 않기로 결정했습니다. 모든 workflow size의 제한이 있지만, 우리는 workflow수를 무한대로 확장할 수 있습니다.
- 만약 당신이 백만개의 task를 실행한다면,단일 워크플로 내에서 모두 구현하지 말고 각각 천 개의 작업을 실행하는 천 개의 하위 워크플로를 만드는 단일 워크플로를 사용해야합니다. 이러한 방법은 각 인스턴스가 bounded될것입니다.
- 하나의 workflow로 만들어지면 하나의머신에 분산되지 않게 처리되기때문에 child를 나누어서 처리하는 방식이 이상적이다.
- multiple hosts: 각 인스턴스 크기가 제한된 사이즈라고 추정해보면, 우리는 그것들을 mutple 머신에 배포할 수 있습니다. 각각 인스턴스가 하나의 머신에 fit 되는것을 보장하기 때문에 시스템 scale out에 실용적입니다.
- 여러 머신에 배포되는 시스템을 만들면, scale out에 보다(하나의 파이프라인으로 처리되는것보다) dynamic하게 처리할 수 있다.
- multiple stores: 만약 당신이 매우매우 커다란 시스템을 원한다면, database 또한 scale out되어야 할것이입니다. single database instance는 bottle nack이 될수 있습니다.
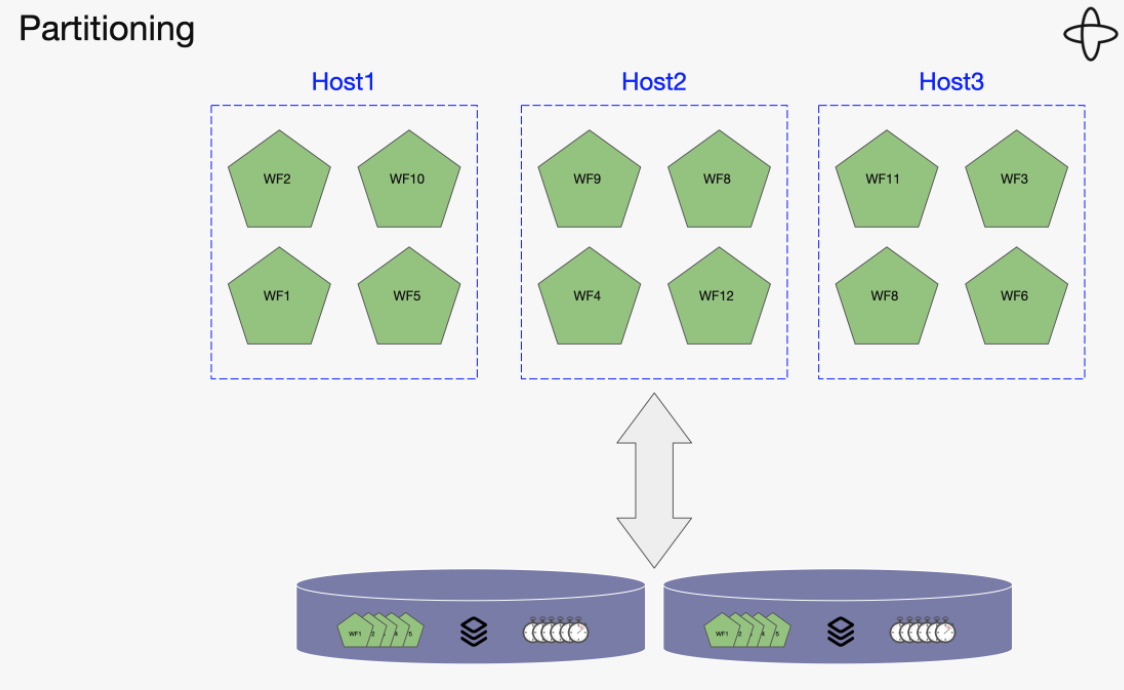
만약 분산 database와 분산 hosts를 handling할수 있다면 scalable한 솔루션인겁니다. 주요 문제는 트랜잭션을 유지할 필요가 있다는 것입니다.multiple database에서 구분된 persistence로 시작되면 당신은 2단계 commits과 같은 복잡한 작업을 수행하지 않는한 보장해 줄 수 없습니다.
분산 환경에서 database의 scalability를 보장해주려면 two phase commit 같은 것들로 지원해줘야하는데 이는 매우 복잡하다.
+
two phase commit: 분산 db에서 transaction commit을 위한 알고리즘.아래와 같이 두 step으로 동작한다.
prepare: commit,rollback준비(transaction이 가능 상태 확인) commit: coordinate가 commit가능 여부를 물어 commit,rollback을 결정, 모두 commit응답이면 실제 commit실행, 단하나의 노드 응답이 rollback이면 모두 rollback